Avaliando a Interpolação Baseada em LCZ em Berlim
Max Anjos
April 24, 2026
Source:vignettes/local_func_modeling_eval.Rmd
local_func_modeling_eval.RmdIntrodução
A quantificação da temperatura do ar interpolada é crucial para a
pesquisa climática, especialmente quando os resultados são usados para
várias aplicações, como planejamento urbano, sistemas de alerta precoce
de ondas de calor e avaliações de saúde pública. O pacote LCZ4r fornece
a função lcz_interp_eval() para avaliar a precisão e
confiabilidade da interpolação baseada em LCZ.
Neste tutorial, demonstraremos como usar esta função para avaliar a interpolação da temperatura do ar em Berlim, Alemanha. Abordaremos:
- Preparação do mapa LCZ para Berlim
- Interpolação espacial da temperatura do ar
- Validação cruzada usando métodos de deixar-um-fora
- Cálculo de métricas de avaliação (RMSE, MAE, sMAPE)
- Visualização do desempenho do modelo por classe LCZ
# Load required packages
if (!require("pacman")) install.packages("pacman")
pacman::p_load(dplyr, sf, tmap, ggplot2, ggExtra, ggpmisc)
library(LCZ4r) # For LCZ and UHI analysis
library(dplyr) # For data manipulation
library(sf) # For vector data manipulation
library(tmap) # For interactive map visualization
library(ggplot2) # For data visualization
library(ggExtra) # For marginal histograms
library(ggpmisc) # For regression equation and R²::: {.callout .callout-note} ::: {.callout .callout-note} Por que Avaliar a Interpolação?
A interpolação espacial da temperatura do ar está sujeita a várias incertezas: - Densidade e distribuição da rede de estações - Variabilidade espacial da temperatura - Suposições e parâmetros do modelo - Dinâmica temporal do clima urbano
A função lcz_interp_eval() ajuda a quantificar essas
incertezas, fornecendo métricas de confiança para suas estimativas
espaciais de temperatura. :::
Preparação do Conjunto de Dados
Carregar Mapa LCZ para Berlim
# Get the LCZ map for Berlin using the LCZ Generator Platform
lcz_map <- lcz_get_map_generator(ID = "8576bde60bfe774e335190f2e8fdd125dd9f4299")
# Optional: Clip the LCZ map to the Berlin area for better focus
lcz_map <- lcz_get_map2(lcz_map, city = "Berlin")
# Visualize the LCZ map
lcz_plot_map(lcz_map)
Mapa LCZ de Berlim mostrando a distribuição espacial das Zonas Climáticas Locais em toda a cidade. Este mapa serve como estrutura espacial para a interpolação de temperatura.
Carregar Dados de Exemplo de Berlim
# Load sample Berlin meteorological data from the LCZ4r package
data("lcz_data")
# View the structure of the dataset
head(lcz_data)
Estrutura do conjunto de dados meteorológicos de Berlim mostrando data, temperatura, ID da estação e coordenadas geográficas.
Visualizar Estações de Monitoramento
# Convert the data to an sf object for spatial visualization
shp_stations <- lcz_data %>%
distinct(Longitude, Latitude, .keep_all = TRUE) %>%
st_as_sf(coords = c("Longitude", "Latitude"), crs = 4326)
# Visualize the stations on an interactive map
tmap_mode("view")
qtm(shp_stations, text = "station",
dots.col = "LCZ",
dots.size = 0.5,
title = "Berlin Meteorological Stations by LCZ Class")Demonstração de Interpolação
Gerar um Mapa de Temperatura
Vamos primeiro criar um mapa de temperatura para um horário específico para entender o que estamos avaliando.
# Map air temperatures for January 2, 2020, at 04:00
my_interp_map <- lcz_interp_map(
lcz_map,
data_frame = lcz_data,
var = "airT",
station_id = "station",
sp.res = 100,
tp.res = "hour",
year = 2020, month = 1, day = 2, hour = 4
)
# Customize the plot with titles and labels
lcz_plot_interp(
my_interp_map,
title = "Thermal Field - Berlin",
subtitle = "January 2, 2020, at 04:00",
caption = "Source: LCZ4r, 2024",
fill = "Temperature [°C]"
)
Mapa de temperatura interpolado para Berlim às 04:00 do dia 2 de janeiro de 2020. O mapa revela uma ilha de calor urbana bem definida nas áreas centrais, com temperaturas mais frias em zonas periféricas e vegetadas.
Avaliação da Interpolação Espacial e Temporal
A questão principal é: Quão confiantes podemos estar no mapa
interpolado? Para responder a isso, usamos a função
lcz_interp_eval() para quantificar os erros associados, o
que é crucial para entender quão bem a interpolação baseada em LCZ
prediz as temperaturas do ar.
Principais Características da lcz_interp_eval()
Esta função avalia a variabilidade da interpolação espacial e temporal usando LCZ como plano de fundo. Ela suporta tanto métodos de interpolação baseados em LCZ quanto convencionais com opções flexíveis:
| Parâmetro | Descrição | Opções |
|---|---|---|
extract.method |
Método para extrair valores LCZ | “simple”, “bilinear” |
LOOCV |
Validação cruzada de deixar-um-fora | TRUE/FALSE |
vg.model |
Modelo de variograma para krigagem | “Sph”, “Exp”, “Gau”, “Mat” |
LCZinterp |
Ativar interpolação baseada em LCZ | TRUE/FALSE |
sp.res |
Resolução espacial em metros | Numérico (ex.: 100, 500) |
tp.res |
Resolução temporal | “hour”, “day”, “month” |
Executando a Avaliação
Nesta demonstração, avaliamos dados horários de temperatura do ar para janeiro de 2020 com resolução espacial de 500 metros usando:
- extract.method: “simple” (atribui classe LCZ com base no valor da célula raster)
- LOOCV: TRUE (validação cruzada de deixar-um-fora para avaliação robusta)
- vg.model: “Sph” (modelo de variograma esférico para krigagem)
- LCZinterp: TRUE (ativa interpolação com LCZ)
Nota: Este processo pode levar vários minutos dependendo do seu sistema. Para janeiro de 2020, há 744 horas (31 dias × 24 horas), e cada hora executa uma validação cruzada em todas as estações. Tome um café enquanto ele executa!
# Evaluate the interpolation with cross-validation
df_eval <- lcz_interp_eval(
lcz_map,
data_frame = lcz_data,
var = "airT",
station_id = "station",
year = 2020,
month = 1,
LOOCV = TRUE,
extract.method = "simple",
sp.res = 500,
tp.res = "hour",
vg.model = "Sph",
LCZinterp = TRUE
)Examinar os Resultados
Vamos examinar a estrutura do data frame de saída. A função retorna um data frame com:
- date: Data e hora da observação
- station: Identificador da estação
- lcz: Classificação da Zona Climática Local
- observed: Valores de temperatura medidos
- predicted: Valores de temperatura interpolados
- residual: Diferença (observado - previsto)
# Check the structure of the evaluation results
str(df_eval)
# View the first few rows
head(df_eval)Estrutura da saída da avaliação mostrando valores observados, valores previstos, resíduos e metadados associados para cada observação.
Calcular Métricas de Avaliação
Com base nos resultados da avaliação, calculamos métricas-chave para quantificar as incertezas da interpolação:
- RMSE (Root Mean Square Error): Mede a magnitude média do erro, dando maior peso a erros grandes
- MAE (Mean Absolute Error): Diferença absoluta média entre valores observados e previstos
- sMAPE (Symmetric Mean Absolute Percent Error): Medida de erro percentual robusta para valores próximos de zero
Agregamos essas métricas por classe LCZ para entender como o desempenho da interpolação varia entre diferentes formas urbanas.
# Calculate evaluation metrics by LCZ class
df_eval_metrics <- df_eval %>%
group_by(lcz) %>%
summarise(
n_obs = n(), # Number of observations
rmse = sqrt(mean((observed - predicted)^2)), # RMSE
mae = mean(abs(observed - predicted)), # MAE
smape = mean(2 * abs(observed - predicted) /
(abs(observed) + abs(predicted)) * 100) # sMAPE
) %>%
arrange(rmse) # Sort by RMSE for easy comparison
# Display the metrics
df_eval_metrics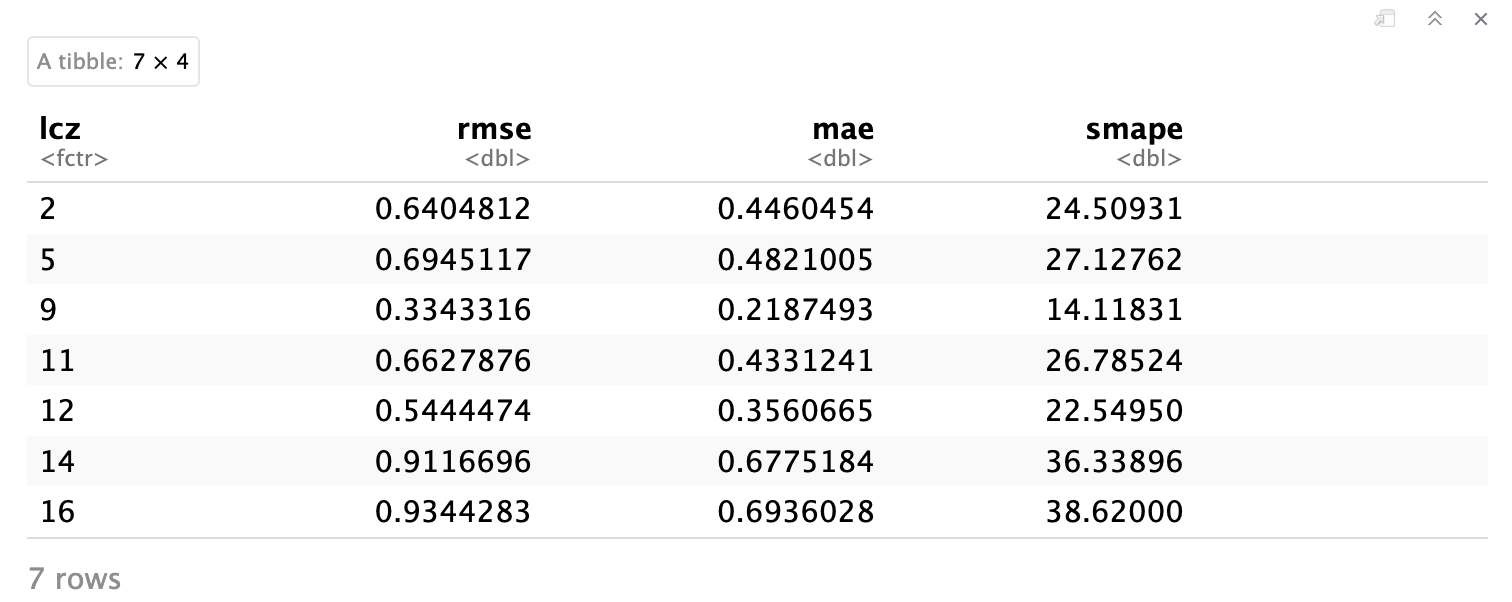
Métricas de avaliação (RMSE, MAE, sMAPE) agregadas por classe LCZ. Valores mais baixos indicam melhor desempenho de interpolação. Observe como diferentes tipos de LCZ mostram níveis variados de precisão de predição.
Visualizando o Desempenho do Modelo
Correlação entre Valores Observados e Previstos
Este gráfico mostra a relação entre temperaturas observadas e previstas, incluindo: - Pontos de dispersão com transparência - Linha de regressão (vermelha) - Contornos de densidade - Equação de regressão e valor de R²
# Correlation plot with regression equation and R²
p1 <- ggplot(df_eval, aes(x = observed, y = predicted)) +
geom_point(alpha = 0.3, color = "#1D9E75", size = 1) +
geom_smooth(method = "lm", color = "red", se = FALSE, size = 1) +
stat_density2d(aes(fill = after_stat(level)), geom = "polygon", alpha = 0.3) +
scale_fill_viridis_c(option = "viridis", name = "Density") +
stat_poly_eq(
aes(label = paste(..eq.label.., ..rr.label.., sep = "~~~")),
formula = y ~ x,
parse = TRUE,
label.x.npc = "left",
label.y.npc = "top",
size = 4
) +
labs(
title = "Observed vs. Predicted Temperatures",
x = "Observed Temperature [°C]",
y = "Predicted Temperature [°C]"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(face = "bold")
)
# Add marginal histograms
p1_with_marginals <- ggMarginal(p1,
type = "histogram",
fill = "#1D9E75",
bins = 30,
alpha = 0.6)
# Print the plot
p1_with_marginals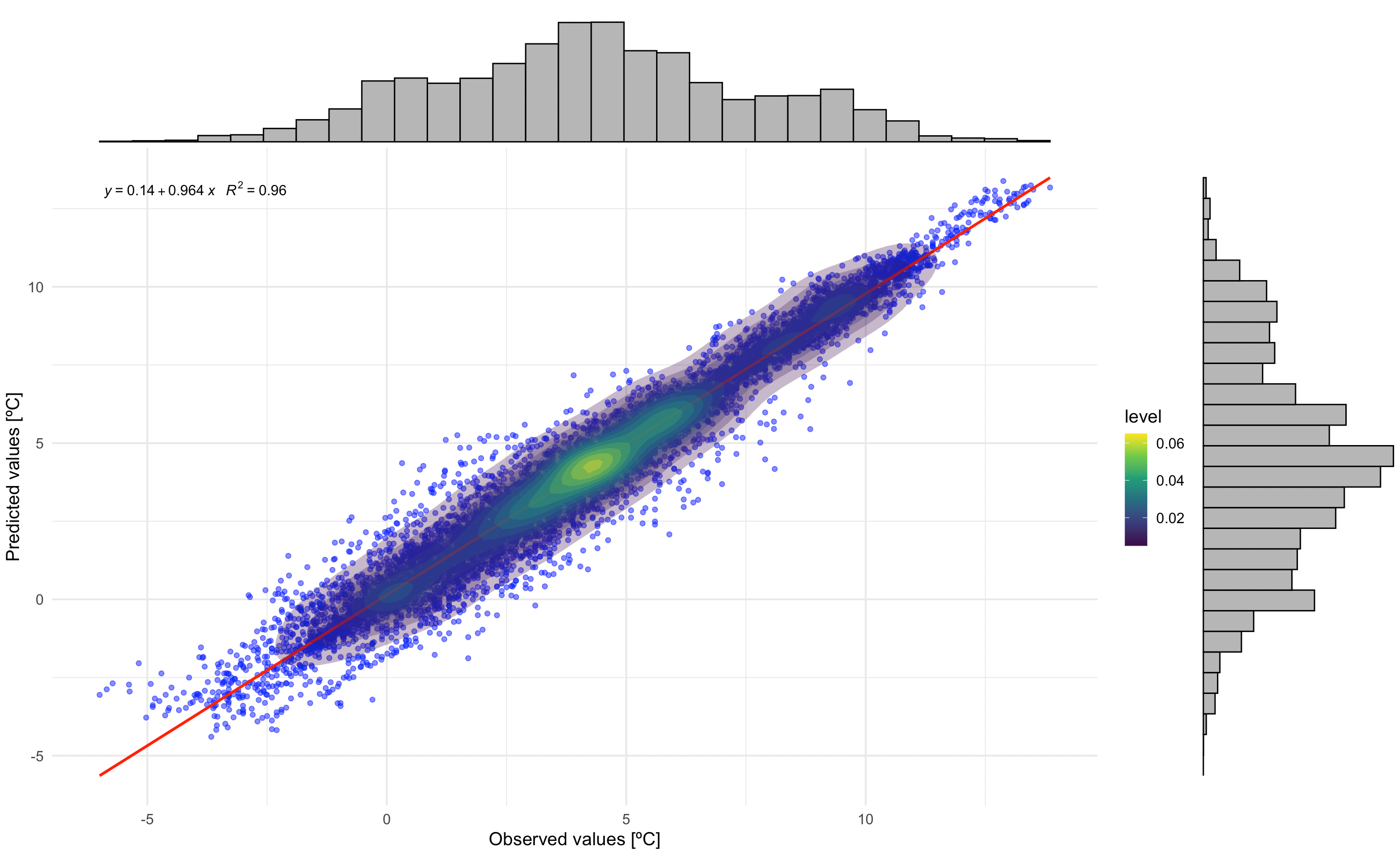
Correlação entre temperaturas observadas e previstas. A equação de regressão e o valor de R² indicam o desempenho do modelo. Os histogramas marginais mostram a distribuição dos valores observados e previstos.
Análise de Resíduos por Classe LCZ
Este gráfico examina os resíduos (observado - previsto) por classe LCZ, ajudando a identificar vieses sistemáticos em diferentes formas urbanas:
- Pontos de dispersão mostrando resíduos individuais
- Linha vermelha horizontal no zero (predição perfeita)
- Linha de suavização Loess (azul) mostrando tendência
- Contornos de densidade indicando concentração de pontos
# Residuals plot by LCZ class
p2 <- ggplot(df_eval, aes(x = observed, y = residual)) +
geom_point(alpha = 0.3, color = "darkgreen", size = 1) +
geom_hline(yintercept = 0, linetype = "dashed", color = "red", linewidth = 0.8) +
geom_smooth(method = "loess", color = "blue", se = FALSE, linewidth = 1) +
stat_density2d(aes(fill = after_stat(level)), geom = "polygon", alpha = 0.3) +
scale_fill_viridis_c(option = "plasma", direction = -1, name = "Density") +
facet_wrap(~ lcz, scales = "free", ncol = 3) +
labs(
title = "Residuals by LCZ Class",
x = "Observed Temperature [°C]",
y = "Residuals [°C]"
) +
theme_minimal(base_size = 12) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(face = "bold"),
strip.text = element_text(size = 12, face = "bold"),
legend.position = "right",
panel.grid.major = element_line(color = "gray90", linetype = "dotted"),
panel.grid.minor = element_blank()
)
# Print the plot
p2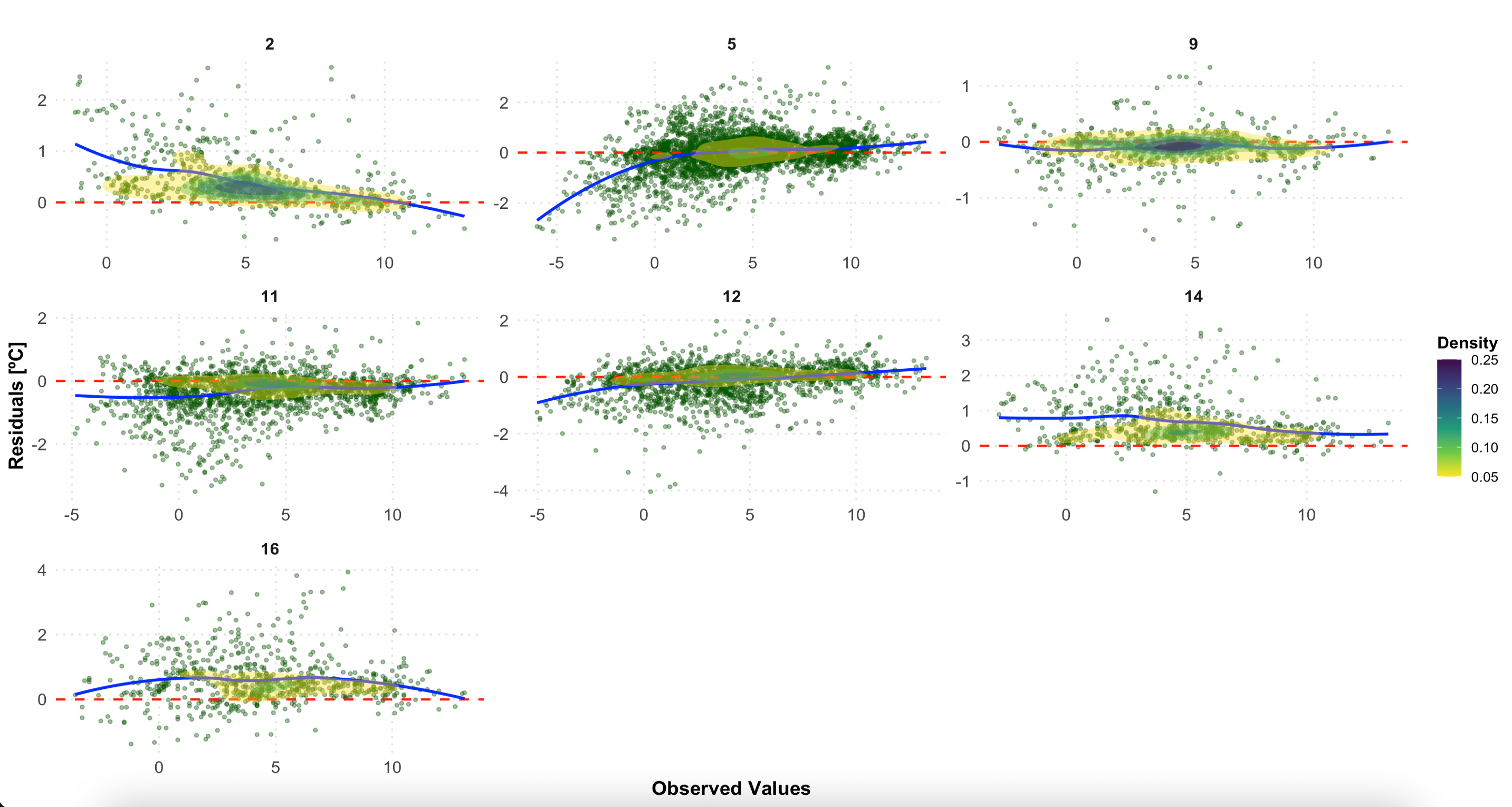
Resíduos por classe LCZ. Uma dispersão aleatória em torno da linha zero (vermelha) indica bom desempenho do modelo. Padrões sistemáticos podem revelar vieses em tipos específicos de LCZ.
Interpretando os Resultados
O que Indica um Bom Desempenho
- Alto valor de R² (> 0,8) indica forte poder preditivo
- Baixo RMSE (< 1,5°C) sugere estimativa precisa da temperatura
- Padrão aleatório de resíduos em torno de zero (sem viés sistemático)
- Desempenho consistente entre classes LCZ
Problemas Potenciais e Soluções
| Problema | Possível Causa | Solução |
|---|---|---|
| Alto RMSE em LCZs específicas | Cobertura esparsa de estações nesse tipo de LCZ | Adicionar mais estações de monitoramento |
| Viés sistemático nos resíduos | Premissas do modelo não atendidas | Tentar diferentes modelos de variograma |
| Baixo desempenho em certos horários | Variabilidade temporal não capturada | Ajustar resolução temporal |
| Alta incerteza em áreas periféricas | Efeitos de borda na interpolação | Expandir área de estudo ou usar diferentes limites |
Opções Avançadas de Avaliação
Comparando Diferentes Métodos de Interpolação
# Compare LCZ-based vs. conventional kriging
eval_lcz <- lcz_interp_eval(
lcz_map, lcz_data, var = "airT", station_id = "station",
year = 2020, month = 1, LOOCV = TRUE,
sp.res = 500, tp.res = "hour",
LCZinterp = TRUE # LCZ-based interpolation
)
eval_conventional <- lcz_interp_eval(
lcz_map, lcz_data, var = "airT", station_id = "station",
year = 2020, month = 1, LOOCV = TRUE,
sp.res = 500, tp.res = "hour",
LCZinterp = FALSE # Conventional kriging
)
# Compare RMSE between methods
rmse_comparison <- data.frame(
Method = c("LCZ-based", "Conventional"),
RMSE = c(sqrt(mean((eval_lcz$observed - eval_lcz$predicted)^2)),
sqrt(mean((eval_conventional$observed - eval_conventional$predicted)^2)))
)Padrões Temporais no Desempenho do Modelo
# Calculate daily RMSE to see temporal patterns
daily_performance <- df_eval %>%
mutate(date = as.Date(date)) %>%
group_by(date, lcz) %>%
summarise(
daily_rmse = sqrt(mean((observed - predicted)^2)),
.groups = "drop"
)
# Visualize temporal variation
ggplot(daily_performance, aes(x = date, y = daily_rmse, color = lcz)) +
geom_line(alpha = 0.7) +
geom_smooth(method = "loess", se = FALSE, size = 1) +
labs(
title = "Daily RMSE Variation by LCZ Class",
x = "Date (January 2020)",
y = "RMSE [°C]",
color = "LCZ Class"
) +
theme_minimal()Salvar os Resultados
# Save the evaluation metrics to CSV
write.csv(df_eval_metrics,
file = "berlin_interpolation_metrics_jan2020.csv",
row.names = FALSE)
# Save the full evaluation data frame
write.csv(df_eval,
file = "berlin_interpolation_evaluation_jan2020.csv",
row.names = FALSE)
# Save plots
ggsave("correlation_plot.png", p1_with_marginals, width = 10, height = 8, dpi = 300)
ggsave("residuals_by_lcz.png", p2, width = 12, height = 10, dpi = 300)Tem sugestões ou feedback?
Você tem uma ideia para melhoria ou encontrou um erro? Adoraríamos saber! Clique no botão abaixo para criar uma nova issue (GitHub) e compartilhar seu feedback ou sugestões diretamente conosco.
Open GitHub issue