评估柏林基于LCZ的插值
Max Anjos
April 24, 2026
Source:vignettes/local_func_modeling_eval.Rmd
local_func_modeling_eval.Rmd介绍
量化插值气温对于气候研究至关重要,特别是当结果用于城市规划、热浪预警系统和公共卫生评估等各种应用时。
LCZ4r 封装提供 lcz_interp_eval() 函数来评估基于 LCZ
的插值精度和可靠性。
在本教程中,我们将演示如何使用此函数来评估德国柏林的气温插值。我们将介绍:
- 柏林 LCZ 地图准备
- 气温空间插值
- 使用留一法进行交叉验证
- 评估指标计算(RMSE、MAE、sMAPE)
- LCZ 类模型性能的可视化
# 加载所需软件包
if (!require("pacman")) install.packages("pacman")
pacman::p_load(dplyr, sf, tmap, ggplot2, ggExtra, ggpmisc)
library(LCZ4r) # 针对LCZ和UHI分析
library(dplyr) # 用于数据处理
library(sf) # 用于向量数据处理
library(tmap) # 用于交互式地图可视化
library(ggplot2) # 用于数据可视化
library(ggExtra) # 对于边缘直方图
library(ggpmisc) # 对于回归方程和 R²为什么评估插值?
气温的空间插值受到各种不确定性的影响: - 站网密度及分布 - 温度的空间变化 - 模型假设和参数 - 城市气候的时间动态
这 lcz_interp_eval()
函数有助于量化这些不确定性,为您的空间温度估计提供置信度指标。
数据集准备
加载柏林 LCZ 地图
# 使用 LCZ 生成器平台获取柏林的 LCZ 地图
lcz_map <- lcz_get_map_generator(ID = "8576bde60bfe774e335190f2e8fdd125dd9f4299")
# 可选:将 LCZ 地图裁剪到柏林区域,以便更好地聚焦
lcz_map <- lcz_get_map2(lcz_map, city = "Berlin")
# 可视化LCZ图
lcz_plot_map(lcz_map)
柏林 LCZ 地图显示了整个城市当地气候带的空间分布。该地图用作温度插值的空间框架。

可视化监测站
# 将数据转换为 sf 对象以进行空间可视化
shp_stations <- lcz_data %>%
distinct(Longitude, Latitude, .keep_all = TRUE) %>%
st_as_sf(coords = c("Longitude", "Latitude"), crs = 4326)
# 在交互式地图上查看站点
tmap_mode("view")
qtm(shp_stations, text = "station",
dots.col = "LCZ",
dots.size = 0.5,
title = "Berlin Meteorological Stations by LCZ Class")插值演示
生成温度图
让我们首先创建特定时间的温度图,以了解我们正在评估的内容。
# 2020年1月2日凌晨4点气温地图
my_interp_map <- lcz_interp_map(
lcz_map,
data_frame = lcz_data,
var = "airT",
station_id = "station",
sp.res = 100,
tp.res = "hour",
year = 2020, month = 1, day = 2, hour = 4
)
# 使用标题和标签自定义图表
lcz_plot_interp(
my_interp_map,
title = "Thermal Field - Berlin",
subtitle = "January 2, 2020, at 04:00",
caption = "Source: LCZ4r, 2024",
fill = "Temperature [°C]"
)
2020 年 1 月 2 日 04:00 柏林的插值温度地图。该地图显示了中心区域明确的城市热岛,而外围和植被区域的温度较低。
空间和时间插值的评估
关键问题是:我们对插值地图有多大信心?为了解决这个问题,我们使用
lcz_interp_eval() 函数来量化相关误差,这对于理解基于 LCZ
的插值预测气温的效果至关重要。
主要特点 lcz_interp_eval()
该函数使用 LCZ 作为背景来评估空间和时间插值的变异性。它支持基于 LCZ 的插值方法和传统的插值方法,并具有灵活的选项:
| 参数 | 描述 | 选项 |
|---|---|---|
extract.method |
提取LCZ值的方法 | “简单”、“双线性” |
LOOCV |
留一法交叉验证 | 对/错 |
vg.model |
克里金法变差函数模型 | “Sph”、“Exp”、“Gau”、“Mat” |
LCZinterp |
激活基于 LCZ 的插值 | 对/错 |
sp.res |
空间分辨率(米) | 数字(例如 100、500) |
tp.res |
时间分辨率 | “小时”、“日”、“月” |
运行评估
在此演示中,我们使用以下方法以 500 米空间分辨率评估 2020 年 1 月的每小时气温数据:
- extract.method:“简单”(根据栅格单元值分配 LCZ 类)
- LOOCV:TRUE(留一交叉验证以进行稳健评估)
- vg.model:“Sph”(克里金法球面变差函数模型)
- LCZinterp:TRUE(激活 LCZ 插值)
注意:此过程可能需要几分钟时间,具体取决于您的系统。 2020年1月,有744小时(31天×24小时),每小时在所有站点之间运行一次交叉验证。当它运行时喝杯咖啡吧!
# 使用交叉验证评估插值结果
df_eval <- lcz_interp_eval(
lcz_map,
data_frame = lcz_data,
var = "airT",
station_id = "station",
year = 2020,
month = 1,
LOOCV = TRUE,
extract.method = "simple",
sp.res = 500,
tp.res = "hour",
vg.model = "Sph",
LCZinterp = TRUE
)计算评估指标
根据评估结果,我们计算关键指标来量化插值不确定性:
- RMSE(均方根误差):测量误差的平均大小,对大误差给予更高的权重
- MAE(平均绝对误差):观测值和预测值之间的平均绝对差
- sMAPE(对称平均绝对百分比误差):对接近零值稳健的百分比误差测量
我们按 LCZ 类别汇总这些指标,以了解插值性能在不同城市形态中的差异。
# 按LCZ类计算评估指标
df_eval_metrics <- df_eval %>%
group_by(lcz) %>%
summarise(
n_obs = n(), # 观测次数
rmse = sqrt(mean((observed - predicted)^2)), # RMSE
mae = mean(abs(observed - predicted)), # MAE
smape = mean(2 * abs(observed - predicted) /
(abs(observed) + abs(predicted)) * 100) # sMAPE
) %>%
arrange(rmse) # 按均方根误差 (RMSE) 排序以便于比较
# 显示指标
df_eval_metrics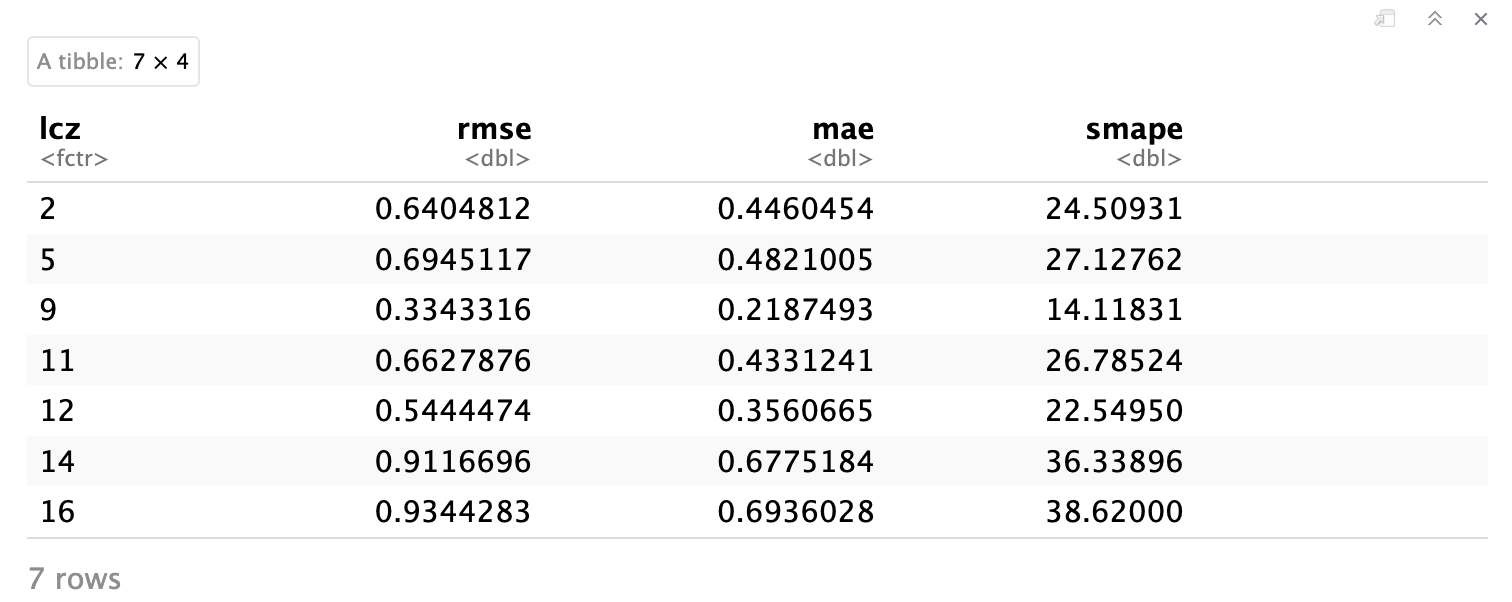
按 LCZ 类别聚合的评估指标(RMSE、MAE、sMAPE)。值越低表示插值性能越好。请注意不同的 LCZ 类型如何显示不同级别的预测精度。
可视化模型性能
观测值和预测值之间的相关性
该图显示了观测温度和预测温度之间的关系,包括: - 具有透明度的散点 - 回归线(红色) - 密度等值线 - 回归方程和R²值
# 相关图,包含回归方程和 R²
p1 <- ggplot(df_eval, aes(x = observed, y = predicted)) +
geom_point(alpha = 0.3, color = "#1D9E75", size = 1) +
geom_smooth(method = "lm", color = "red", se = FALSE, size = 1) +
stat_density2d(aes(fill = after_stat(level)), geom = "polygon", alpha = 0.3) +
scale_fill_viridis_c(option = "viridis", name = "Density") +
stat_poly_eq(
aes(label = paste(..eq.label.., ..rr.label.., sep = "~~~")),
formula = y ~ x,
parse = TRUE,
label.x.npc = "left",
label.y.npc = "top",
size = 4
) +
labs(
title = "Observed vs. Predicted Temperatures",
x = "Observed Temperature [°C]",
y = "Predicted Temperature [°C]"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(face = "bold")
)
# 添加边际直方图
p1_with_marginals <- ggMarginal(p1,
type = "histogram",
fill = "#1D9E75",
bins = 30,
alpha = 0.6)
# 打印图表
p1_with_marginals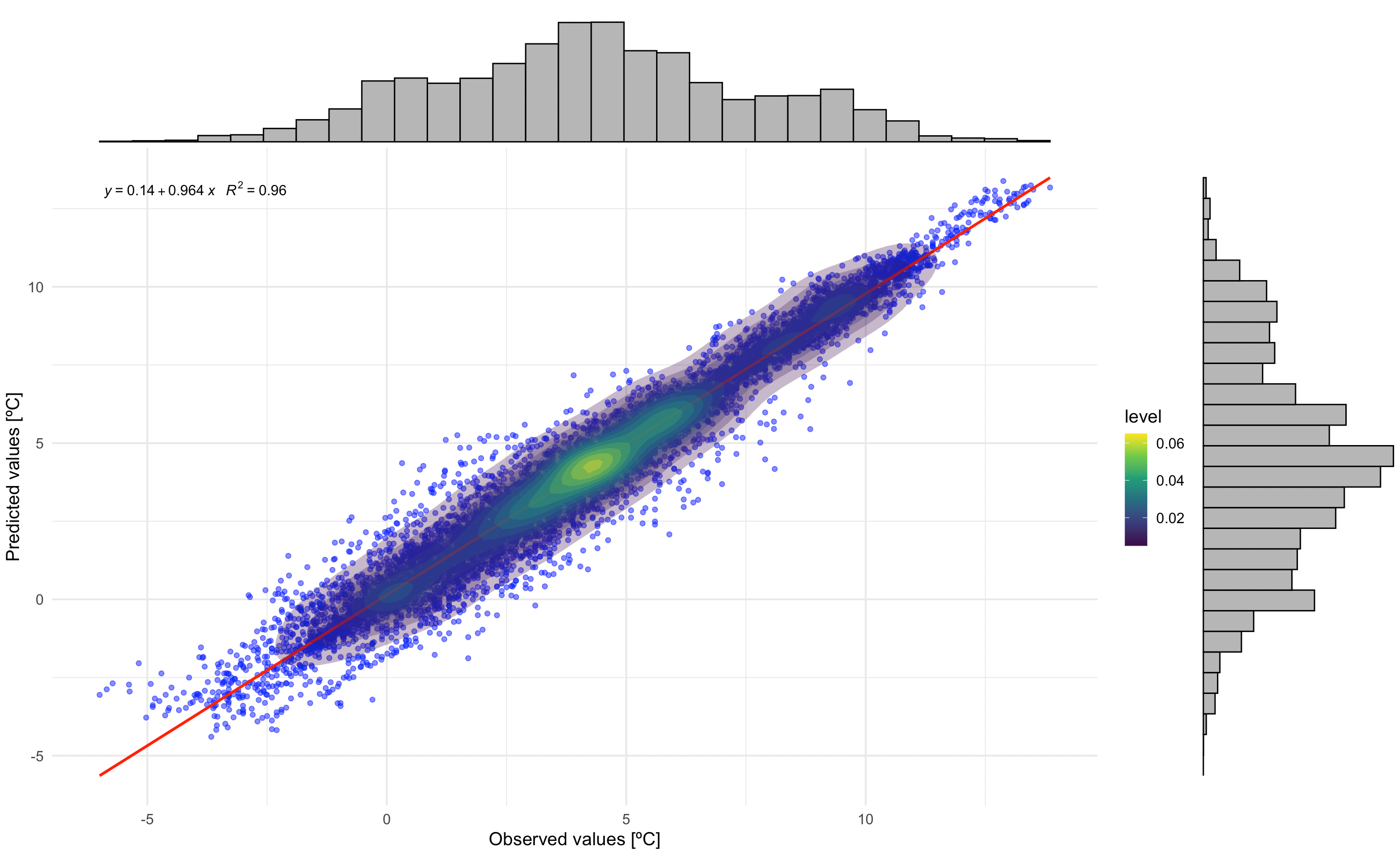
观测温度和预测温度之间的相关性。回归方程和 R² 值表明模型性能。边缘直方图显示观测值和预测值的分布。
按 LCZ 类别进行残差分析
该图检查了 LCZ 类别的残差(观察到的 - 预测的),有助于识别不同城市形态中的系统偏差:
- 散点显示各个残差
- 水平红线为零(完美预测)
- 黄土平滑线(蓝色)显示趋势
- 密度等值线指示点浓度
# 按LCZ类别划分的残差图
p2 <- ggplot(df_eval, aes(x = observed, y = residual)) +
geom_point(alpha = 0.3, color = "darkgreen", size = 1) +
geom_hline(yintercept = 0, linetype = "dashed", color = "red", linewidth = 0.8) +
geom_smooth(method = "loess", color = "blue", se = FALSE, linewidth = 1) +
stat_density2d(aes(fill = after_stat(level)), geom = "polygon", alpha = 0.3) +
scale_fill_viridis_c(option = "plasma", direction = -1, name = "Density") +
facet_wrap(~ lcz, scales = "free", ncol = 3) +
labs(
title = "Residuals by LCZ Class",
x = "Observed Temperature [°C]",
y = "Residuals [°C]"
) +
theme_minimal(base_size = 12) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(face = "bold"),
strip.text = element_text(size = 12, face = "bold"),
legend.position = "right",
panel.grid.major = element_line(color = "gray90", linetype = "dotted"),
panel.grid.minor = element_blank()
)
# 打印图表
p2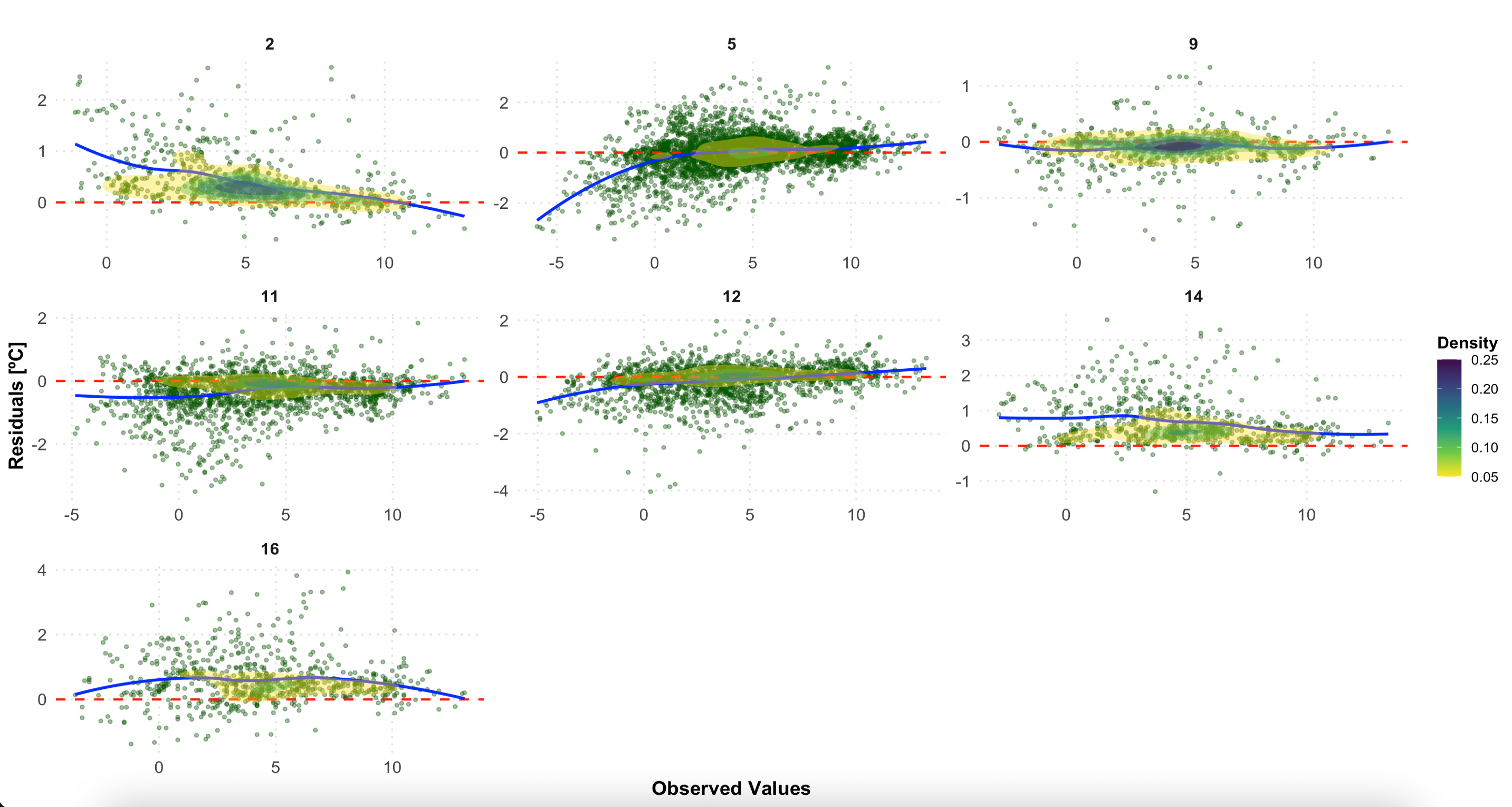
按 LCZ 类别划分的残差。零(红线)周围的随机散布表明模型性能良好。系统模式可能揭示特定 LCZ 类型的偏差。
高级评估选项
比较不同的插值方法
# 比较基于LCZ的克里金法与传统克里金法
eval_lcz <- lcz_interp_eval(
lcz_map, lcz_data, var = "airT", station_id = "station",
year = 2020, month = 1, LOOCV = TRUE,
sp.res = 500, tp.res = "hour",
LCZinterp = TRUE # LCZ-based interpolation
)
eval_conventional <- lcz_interp_eval(
lcz_map, lcz_data, var = "airT", station_id = "station",
year = 2020, month = 1, LOOCV = TRUE,
sp.res = 500, tp.res = "hour",
LCZinterp = FALSE # Conventional kriging
)
# 比较不同方法的均方根误差 (RMSE)
rmse_comparison <- data.frame(
Method = c("LCZ-based", "Conventional"),
RMSE = c(sqrt(mean((eval_lcz$observed - eval_lcz$predicted)^2)),
sqrt(mean((eval_conventional$observed - eval_conventional$predicted)^2)))
)模型性能中的时间模式
# 计算每日均方根误差 (RMSE) 以观察时间模式
daily_performance <- df_eval %>%
mutate(date = as.Date(date)) %>%
group_by(date, lcz) %>%
summarise(
daily_rmse = sqrt(mean((observed - predicted)^2)),
.groups = "drop"
)
# 可视化时间变化
ggplot(daily_performance, aes(x = date, y = daily_rmse, color = lcz)) +
geom_line(alpha = 0.7) +
geom_smooth(method = "loess", se = FALSE, size = 1) +
labs(
title = "Daily RMSE Variation by LCZ Class",
x = "Date (January 2020)",
y = "RMSE [°C]",
color = "LCZ Class"
) +
theme_minimal()保存结果
# 将评估指标保存到 CSV 文件
write.csv(df_eval_metrics,
file = "berlin_interpolation_metrics_jan2020.csv",
row.names = FALSE)
# 保存完整的评估数据框
write.csv(df_eval,
file = "berlin_interpolation_evaluation_jan2020.csv",
row.names = FALSE)
# 保存地块
ggsave("correlation_plot.png", p1_with_marginals, width = 10, height = 8, dpi = 300)
ggsave("residuals_by_lcz.png", p2, width = 12, height = 10, dpi = 300)