Evaluación de la interpolación basada en LCZ en Berlín
Max Anjos
April 24, 2026
Source:vignettes/local_func_modeling_eval.Rmd
local_func_modeling_eval.RmdIntroducción
Cuantificar la temperatura del aire interpolada es crucial para la
investigación climática, especialmente cuando los resultados se utilizan
para diversas aplicaciones, como planificación urbana, sistemas de
alerta temprana de olas de calor y evaluaciones de salud pública. El
paquete LCZ4r proporciona la lcz_interp_eval() función para
evaluar la precisión y confiabilidad de la interpolación basada en
LCZ.
En este tutorial, demostraremos cómo utilizar esta función para evaluar la interpolación de la temperatura del aire en Berlín, Alemania. Cubriremos:
- Preparación del mapa LCZ para Berlín
- Interpolación espacial de la temperatura del aire
- Validación cruzada utilizando métodos de dejar uno fuera
- Cálculo de métricas de evaluación (RMSE, MAE, sMAPE)
- Visualización del rendimiento del modelo por clase LCZ
# Cargar los paquetes necesarios
if (!require("pacman")) install.packages("pacman")
pacman::p_load(dplyr, sf, tmap, ggplot2, ggExtra, ggpmisc)
library(LCZ4r) # Para el análisis de LCZ y UHI
library(dplyr) # Para la manipulación de datos
library(sf) # Para la manipulación de datos vectoriales
library(tmap) # Para visualización interactiva de mapas
library(ggplot2) # Para la visualización de datos
library(ggExtra) # Para histogramas marginales
library(ggpmisc) # Para la ecuación de regresión y R²¿Por qué evaluar la interpolación?
La interpolación espacial de la temperatura del aire está sujeta a varias incertidumbres: - Densidad y distribución de la red de estaciones. - Variabilidad espacial de la temperatura. - Supuestos y parámetros del modelo. - Dinámica temporal del clima urbano.
El lcz_interp_eval() La función ayuda a cuantificar
estas incertidumbres y proporciona métricas de confianza para sus
estimaciones de temperatura espacial.
Preparación del conjunto de datos
Cargar mapa LCZ para Berlín
# Obtén el mapa LCZ de Berlín usando la plataforma Generador de LCZ
lcz_map <- lcz_get_map_generator(ID = "8576bde60bfe774e335190f2e8fdd125dd9f4299")
# Opcional: Recorte el mapa de la ZLC al área de Berlín para un mejor enfoque
lcz_map <- lcz_get_map2(lcz_map, city = "Berlin")
# Visualice el mapa de LCZ
lcz_plot_map(lcz_map)
Mapa LCZ de Berlín que muestra la distribución espacial de las zonas climáticas locales en toda la ciudad. Este mapa sirve como marco espacial para la interpolación de temperaturas.
Cargar datos de muestra de Berlín
# Cargar datos meteorológicos de muestra de Berlín del paquete LCZ4r.
data("lcz_data")
# Visualice la estructura del conjunto de datos
head(lcz_data)
Estructura del conjunto de datos meteorológicos de Berlín que muestra fecha, temperatura, ID de estación y coordenadas geográficas.
Visualice estaciones de monitoreo
# Convierta los datos a un objeto sf para visualización espacial
shp_stations <- lcz_data %>%
distinct(Longitude, Latitude, .keep_all = TRUE) %>%
st_as_sf(coords = c("Longitude", "Latitude"), crs = 4326)
# Visualiza las estaciones en un mapa interactivo
tmap_mode("view")
qtm(shp_stations, text = "station",
dots.col = "LCZ",
dots.size = 0.5,
title = "Estaciones meteorológicas de Berlín por clase LCZ")Demostración de interpolación
Generar un mapa de temperatura
Primero creemos un mapa de temperatura para un tiempo específico para entender lo que estamos evaluando.
# Mapa de temperaturas del aire para el 2 de enero de 2020 a las 04:00
my_interp_map <- lcz_interp_map(
lcz_map,
data_frame = lcz_data,
var = "airT",
station_id = "station",
sp.res = 100,
tp.res = "hour",
year = 2020, month = 1, day = 2, hour = 4
)
# Personaliza la trama con títulos y etiquetas
lcz_plot_interp(
my_interp_map,
title = "Thermal Field - Berlin",
subtitle = "January 2, 2020, at 04:00",
caption = "Source: LCZ4r, 2024",
fill = "Temperature [°C]"
)
Mapa de temperatura interpolado de Berlín a las 04:00 del 2 de enero de 2020. El mapa revela una isla de calor urbana bien definida en las zonas centrales, con temperaturas más frías en las zonas periféricas y con vegetación.
Evaluación de la interpolación espacial y temporal
La pregunta clave es: ¿Qué tan seguros podemos estar en el
mapa interpolado? Para abordar esto, utilizamos el
lcz_interp_eval() funcionan para cuantificar los errores
asociados, lo cual es crucial para comprender qué tan bien la
interpolación basada en LCZ predice las temperaturas del aire.
Características clave de lcz_interp_eval()
Esta función evalúa la variabilidad de la interpolación espacial y temporal utilizando LCZ como fondo. Admite métodos de interpolación convencionales y basados en LCZ con opciones flexibles:
| Parámetro | Descripción | Opciones |
|---|---|---|
extract.method |
Método para extraer valores LCZ | “simple”, “bilineal” |
LOOCV |
Validación cruzada con exclusión de uno | VERDADERO/FALSO |
vg.model |
Modelo de variograma para kriging | “Sph”, “Exp”, “Gau”, “Mat” |
LCZinterp |
Activar la interpolación basada en LCZ | VERDADERO/FALSO |
sp.res |
Resolución espacial en metros | Numérico (por ejemplo, 100, 500) |
tp.res |
Resolución temporal | “hora”, “día”, “mes” |
Ejecutando la evaluación
En esta demostración, evaluamos los datos de temperatura del aire por hora para enero de 2020 con una resolución espacial de 500 metros usando:
- extract.method: “simple” (asigna la clase LCZ según el valor de la celda ráster)
- LOOCV: VERDADERO (validación cruzada de dejar uno fuera para una evaluación sólida)
- vg.model: “Sph” (modelo de variograma esférico para kriging)
- LCZinterp: TRUE (activa la interpolación con LCZ)
Nota: Este proceso puede tardar varios minutos dependiendo de su sistema. Para enero de 2020, hay 744 horas (31 días × 24 horas) y cada hora realiza una validación cruzada en todas las estaciones. ¡Toma un café mientras corre!
# Evaluar la interpolación mediante validación cruzada
df_eval <- lcz_interp_eval(
lcz_map,
data_frame = lcz_data,
var = "airT",
station_id = "station",
year = 2020,
month = 1,
LOOCV = TRUE,
extract.method = "simple",
sp.res = 500,
tp.res = "hour",
vg.model = "Sph",
LCZinterp = TRUE
)Examinar los resultados
Examinemos la estructura del marco de datos de salida. La función devuelve un marco de datos con:
- fecha: Marca de tiempo de la observación
- estación: Identificador de estación
- lcz: Clasificación de zonas climáticas locales
- observado: Valores de temperatura medidos
- predicho: valores de temperatura interpolados
- residual: Diferencia (observada - prevista)
# Verifique la estructura de los resultados de la evaluación
str(df_eval)
# Vea las primeras filas
head(df_eval)Estructura del resultado de la evaluación que muestra los valores observados, los valores predichos, los residuos y los metadatos asociados para cada observación.
Calcular métricas de evaluación
Con base en los resultados de la evaluación, calculamos métricas clave para cuantificar las incertidumbres de la interpolación:
- RMSE (Error cuadrático medio): Mide la magnitud promedio del error, otorgando mayor peso a los errores grandes.
- MAE (Error absoluto medio): diferencia absoluta promedio entre los valores observados y predichos
- sMAPE (Error porcentual absoluto medio simétrico): Medida de error porcentual robusta a valores cercanos a cero
Agregamos estas métricas por clase LCZ para comprender cómo varía el rendimiento de la interpolación entre diferentes formas urbanas.
# Calculate evaluation metrics by LCZ class
df_eval_metrics <- df_eval %>%
group_by(lcz) %>%
summarise(
n_obs = n(), # Número de observaciones
rmse = sqrt(mean((observed - predicted)^2)), # RMSE
mae = mean(abs(observed - predicted)), # MAE
smape = mean(2 * abs(observed - predicted) /
(abs(observed) + abs(predicted)) * 100) # sMAPE
) %>%
arrange(rmse) # Ordenar por RMSE para una comparación sencilla
# Mostrar las métricas
df_eval_metrics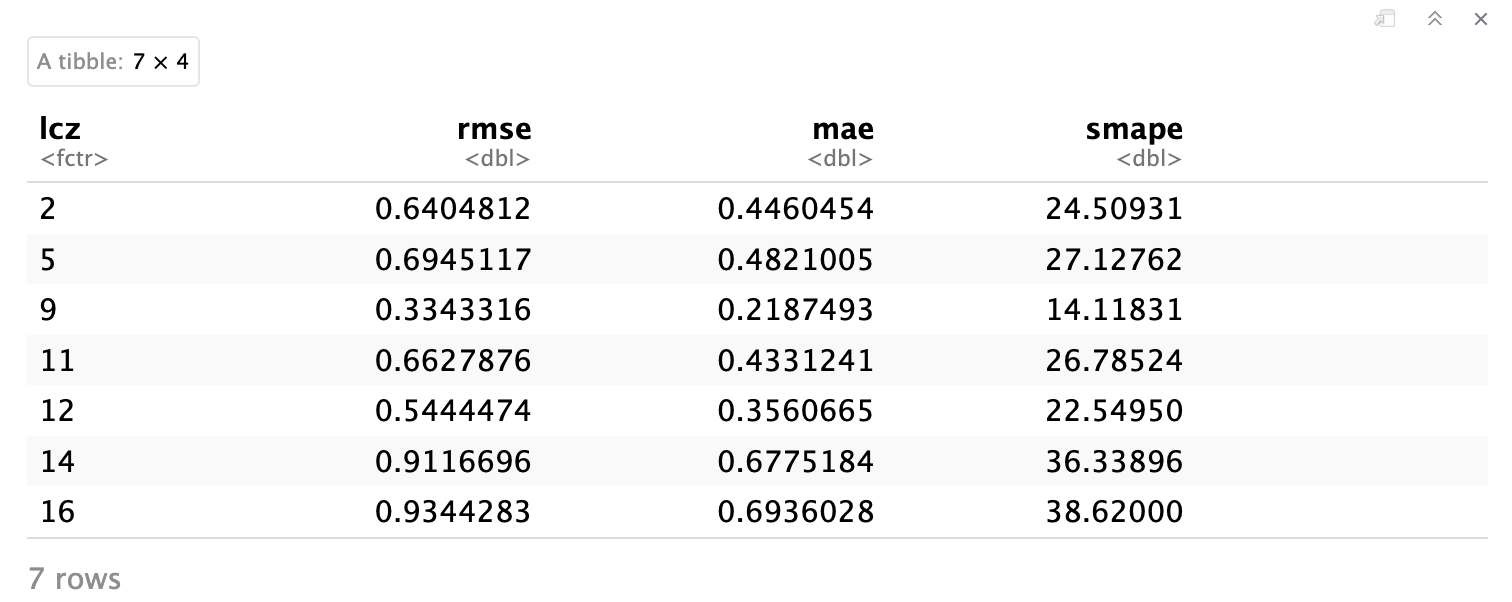
Métricas de evaluación (RMSE, MAE, sMAPE) agregadas por clase LCZ. Los valores más bajos indican un mejor rendimiento de la interpolación. Observe cómo los diferentes tipos de LCZ muestran distintos niveles de precisión de predicción.
Visualización del rendimiento del modelo
Correlación entre valores observados y pronosticados
Este gráfico muestra la relación entre las temperaturas observadas y previstas, incluyendo: - Puntos de dispersión con transparencia. - Línea de regresión (roja) - Contornos de densidad - Ecuación de regresión y valor R²
# Gráfico de correlación con ecuación de regresión y R²
p1 <- ggplot(df_eval, aes(x = observed, y = predicted)) +
geom_point(alpha = 0.3, color = "#1D9E75", size = 1) +
geom_smooth(method = "lm", color = "red", se = FALSE, size = 1) +
stat_density2d(aes(fill = after_stat(level)), geom = "polygon", alpha = 0.3) +
scale_fill_viridis_c(option = "viridis", name = "Density") +
stat_poly_eq(
aes(label = paste(..eq.label.., ..rr.label.., sep = "~~~")),
formula = y ~ x,
parse = TRUE,
label.x.npc = "left",
label.y.npc = "top",
size = 4
) +
labs(
title = "Observed vs. Predicted Temperatures",
x = "Observed Temperature [°C]",
y = "Predicted Temperature [°C]"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(face = "bold")
)
# Agregar histogramas marginales
p1_with_marginals <- ggMarginal(p1,
type = "histogram",
fill = "#1D9E75",
bins = 30,
alpha = 0.6)
# Imprimir el gráfico
p1_with_marginals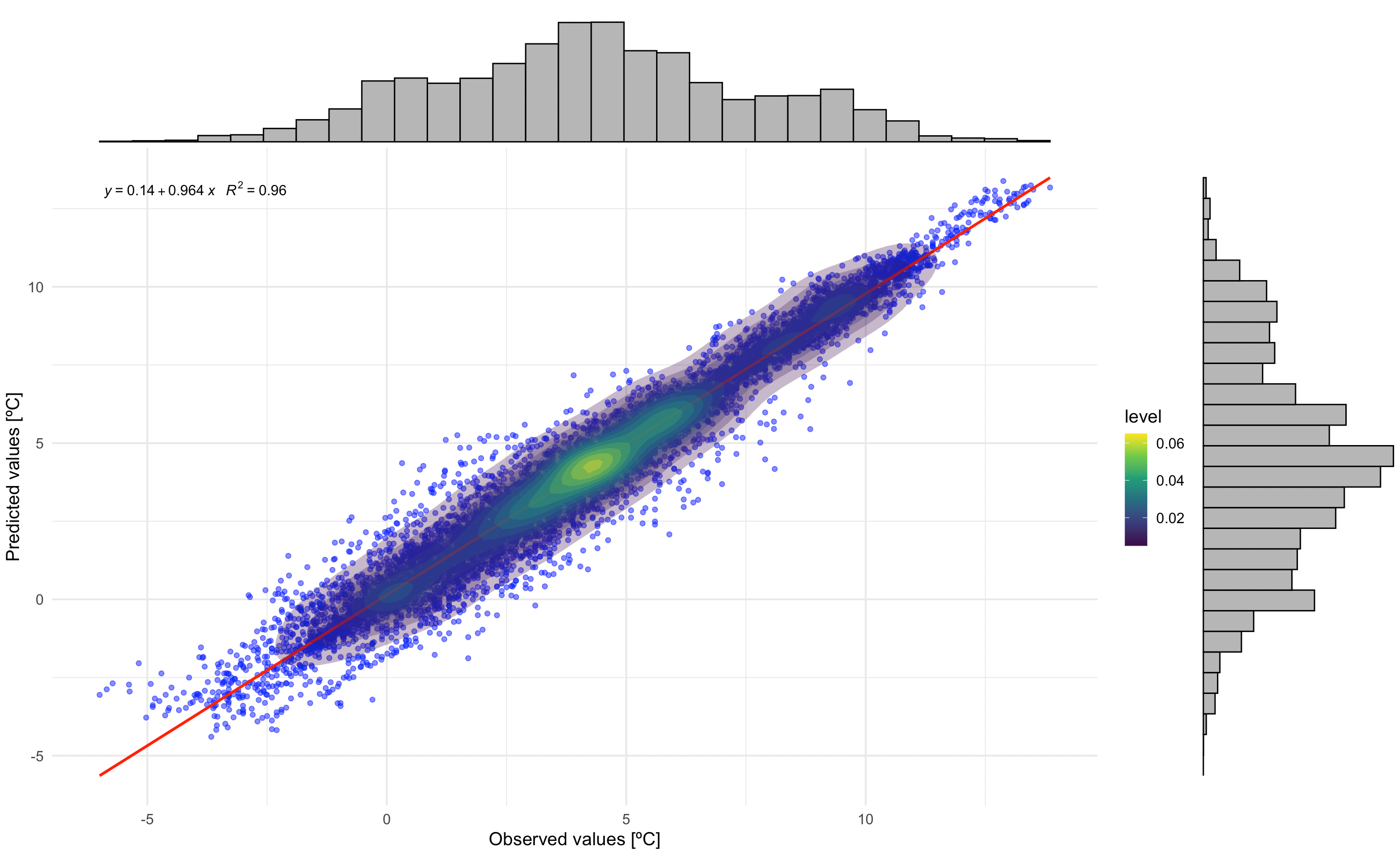
Correlación entre temperaturas observadas y previstas. La ecuación de regresión y el valor R² indican el rendimiento del modelo. Los histogramas marginales muestran la distribución de los valores observados y predichos.
Análisis residual por clase LCZ
Este gráfico examina los residuos (observados - predichos) por clase LCZ, lo que ayuda a identificar sesgos sistemáticos en diferentes formas urbanas:
- Puntos de dispersión que muestran residuos individuales
- Línea roja horizontal en cero (predicción perfecta)
- Línea de suavizado de pérdidas (azul) que muestra la tendencia
- Contornos de densidad que indican concentración puntual
# Gráfico de residuos por clase LCZ
p2 <- ggplot(df_eval, aes(x = observed, y = residual)) +
geom_point(alpha = 0.3, color = "darkgreen", size = 1) +
geom_hline(yintercept = 0, linetype = "dashed", color = "red", linewidth = 0.8) +
geom_smooth(method = "loess", color = "blue", se = FALSE, linewidth = 1) +
stat_density2d(aes(fill = after_stat(level)), geom = "polygon", alpha = 0.3) +
scale_fill_viridis_c(option = "plasma", direction = -1, name = "Density") +
facet_wrap(~ lcz, scales = "free", ncol = 3) +
labs(
title = "Residuals by LCZ Class",
x = "Observed Temperature [°C]",
y = "Residuals [°C]"
) +
theme_minimal(base_size = 12) +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(face = "bold"),
strip.text = element_text(size = 12, face = "bold"),
legend.position = "right",
panel.grid.major = element_line(color = "gray90", linetype = "dotted"),
panel.grid.minor = element_blank()
)
# Imprimir el gráfico
p2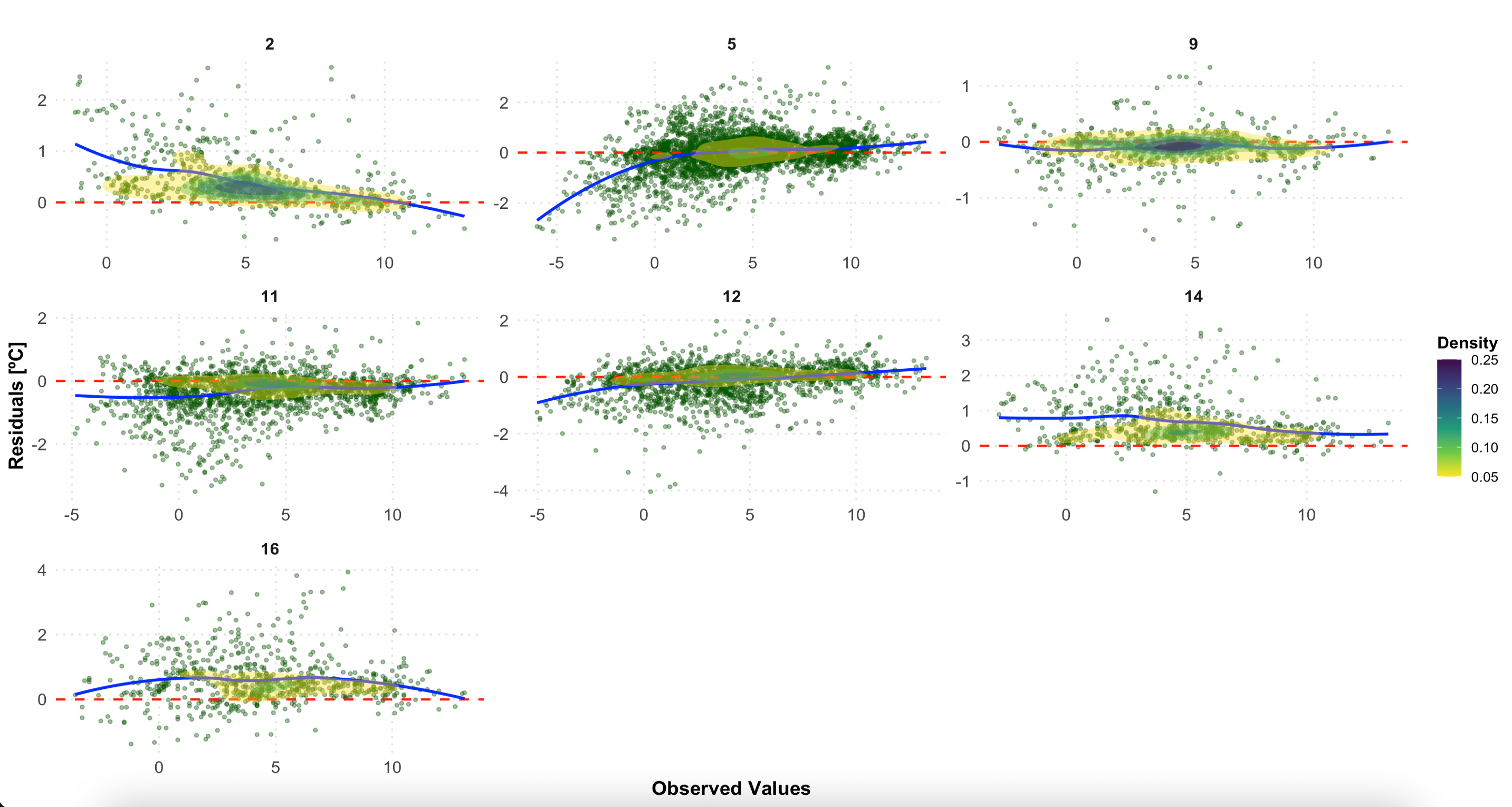
Residuos por clase LCZ. Una dispersión aleatoria alrededor de cero (línea roja) indica un buen rendimiento del modelo. Los patrones sistemáticos pueden revelar sesgos en tipos específicos de LCZ.
Interpretación de los resultados
Cómo se ve un buen desempeño
- Valor R² alto (> 0,8) indica un fuerte poder predictivo
- RMSE bajo (< 1,5 °C) sugiere una estimación precisa de la temperatura
- Patrón residual aleatorio alrededor de cero (sin sesgo sistemático)
- Rendimiento constante en todas las clases LCZ
Posibles problemas y soluciones
| Problema | Posible causa | Solución |
|---|---|---|
| Alto RMSE en LCZ específicas | Escasa cobertura de estaciones en ese tipo LCZ | Agregar más estaciones de monitoreo |
| Sesgo sistemático en los residuos | Supuestos del modelo no cumplidos | Pruebe diferentes modelos de variogramas |
| Mal desempeño en determinadas horas | Variabilidad temporal no capturada | Ajustar la resolución temporal |
| Alta incertidumbre en zonas periféricas | Efectos de borde en interpolación | Ampliar el área de estudio o utilizar límites diferentes |
Opciones de evaluación avanzadas
Comparación de diferentes métodos de interpolación
# Comparación entre el kriging basado en LCZ y el kriging convencional
eval_lcz <- lcz_interp_eval(
lcz_map, lcz_data, var = "airT", station_id = "station",
year = 2020, month = 1, LOOCV = TRUE,
sp.res = 500, tp.res = "hour",
LCZinterp = TRUE # Interpolación basada en LCZ
)
eval_conventional <- lcz_interp_eval(
lcz_map, lcz_data, var = "airT", station_id = "station",
year = 2020, month = 1, LOOCV = TRUE,
sp.res = 500, tp.res = "hour",
LCZinterp = FALSE # Kriging convencional
)
# Comparar el RMSE entre los métodos
rmse_comparison <- data.frame(
Method = c("LCZ-based", "Conventional"),
RMSE = c(sqrt(mean((eval_lcz$observed - eval_lcz$predicted)^2)),
sqrt(mean((eval_conventional$observed - eval_conventional$predicted)^2)))
)Patrones temporales en el rendimiento del modelo
# Calcula el RMSE diario para ver patrones temporales
daily_performance <- df_eval %>%
mutate(date = as.Date(date)) %>%
group_by(date, lcz) %>%
summarise(
daily_rmse = sqrt(mean((observed - predicted)^2)),
.groups = "drop"
)
# Visualizar la variación temporal
ggplot(daily_performance, aes(x = date, y = daily_rmse, color = lcz)) +
geom_line(alpha = 0.7) +
geom_smooth(method = "loess", se = FALSE, size = 1) +
labs(
title = "Daily RMSE Variation by LCZ Class",
x = "Date (January 2020)",
y = "RMSE [°C]",
color = "LCZ Class"
) +
theme_minimal()Guardar resultados
# Guarda las métricas de evaluación en formato CSV
write.csv(df_eval_metrics,
file = "berlin_interpolation_metrics_jan2020.csv",
row.names = FALSE)
# Guardar el marco de datos de evaluación completo
write.csv(df_eval,
file = "berlin_interpolation_evaluation_jan2020.csv",
row.names = FALSE)
# Guardar parcelas
ggsave("correlation_plot.png", p1_with_marginals, width = 10, height = 8, dpi = 300)
ggsave("residuals_by_lcz.png", p2, width = 12, height = 10, dpi = 300)¿Tiene comentarios o sugerencias?
¿Tiene una idea para mejorar o detectó un error? ¡Nos encantaría saber de usted! Haga clic en el botón a continuación para crear una nueva edición (GitHub) y compartir sus comentarios o sugerencias directamente con nosotros.
Abrir incidencia en GitHub